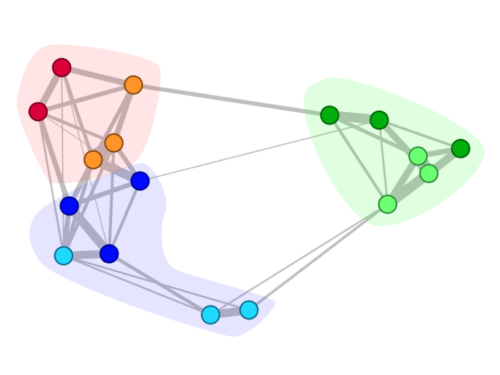
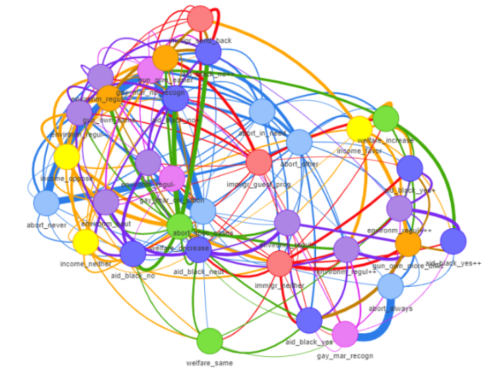
Welcome to ResIN!
ResIN is a holistic quantitative method for analysing attitude systems (even if it can be applied also to the analysis…






Seamless Theme Just Pretty, made by Altervista
Create a website and earn with Altervista - Disclaimer - Report Abuse